
Specify 6 Desktop Application
Specify 6 is a database platform for museum and herbarium research data. It manages species and specimen information for computerizing biological collections, tracking museum specimen transactions, linking images to specimen records and publishing catalog data to the Internet. Specify 6 is written in Java for Windows, Mac OS X, and Linux computers and uses the relational data manager, MySQL, as its data engine. Specify, Java, and MySQL are free and open-source. Specify 7 is a wholly-new web platform, the next generation of Specify which operates within a web browser using Javascript and with Linux server code written in Python. Specify 7 works with the same MySQL database design as Specify 6, they can run simultaneously on the same collection database.
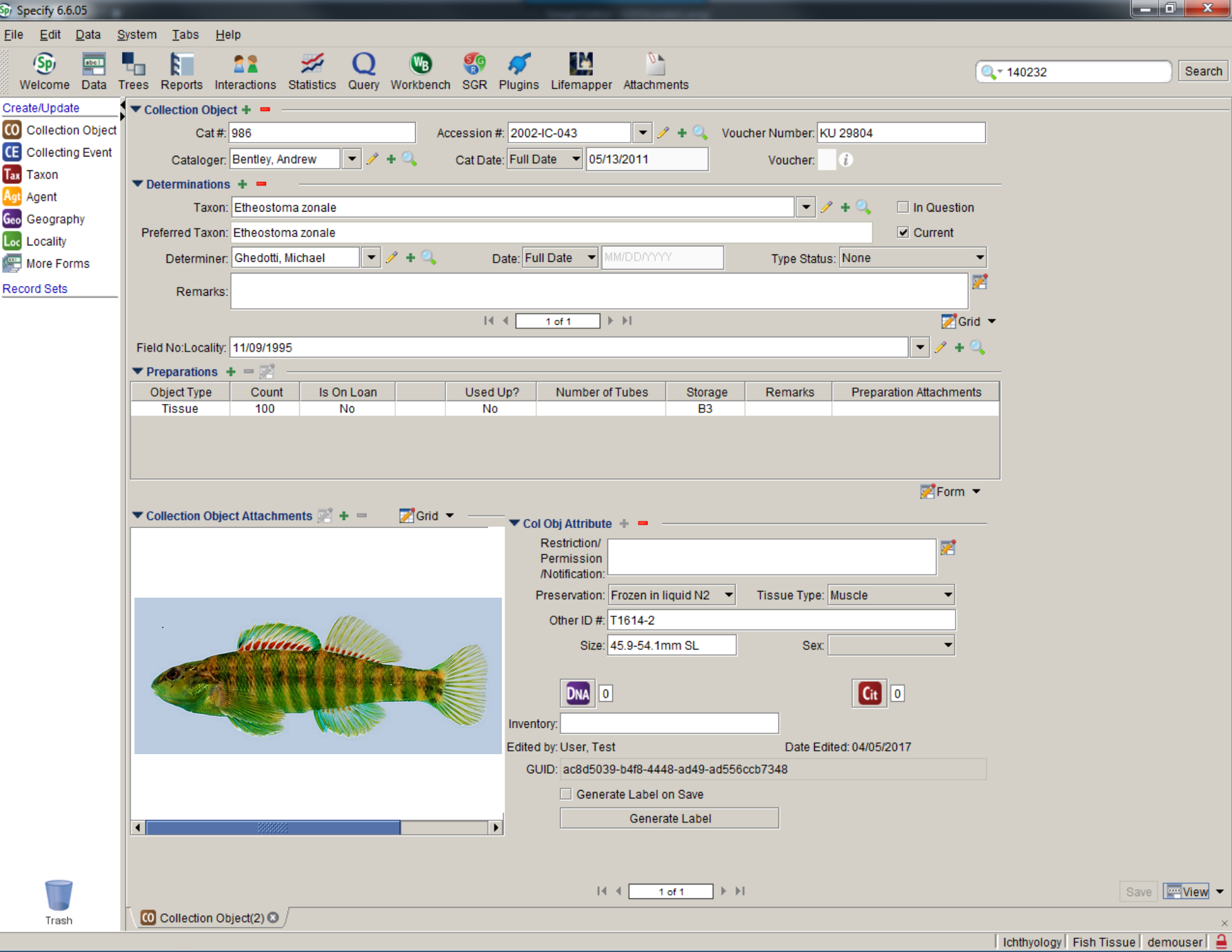
Specify supports data from specimens, taxonomic and stratigraphic classifications, field notebooks, DNA sequence runs, literature references, as well as from other primary sources. It also manages the information associated with repository agreements, accessions, conservation treatments, collection object containers, images, and document attachments.
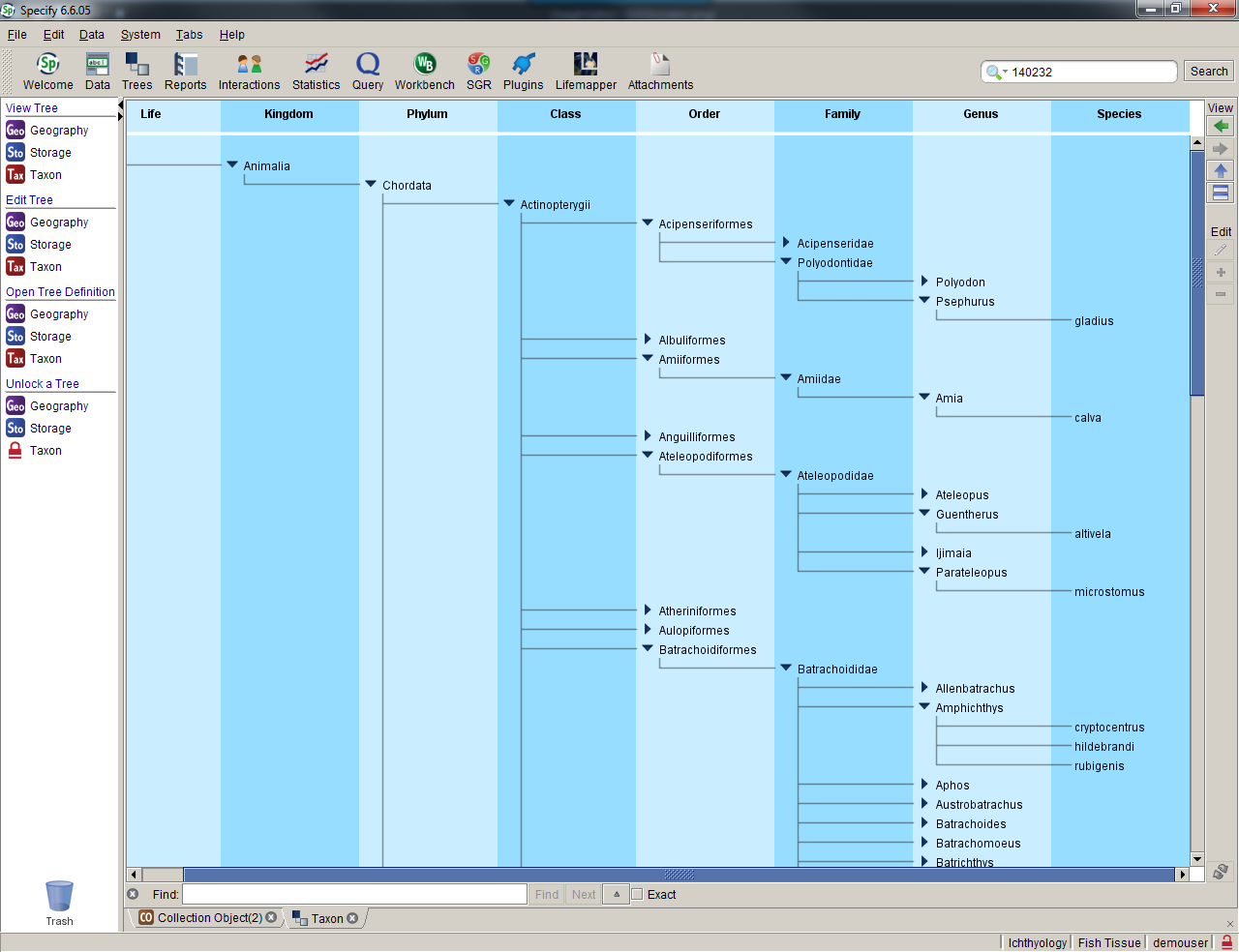
Data fields in Specify’s form windows can be selected, organized, re-named, and re-sized to suit your curatorial preferences and to eliminate the need for tabbing through multiple data forms. Specify’s “tree” data windows for taxonomy, geography, storage location, chronostratigraphy and lithostratigraphy provide intuitive access to hierarchical data for editing, drag-and-drop synonymization, re-parenting, and for discovering linked collection objects.
Retrieving data is facilitated by Specify’s full-text ‘Simple Search’. For complex fielded queries, the ‘Query Builder’ provides access to every data table and field. The Query Builder includes the expected complement of comparison operators for each search field, along with display, sort, distinct, and count options. Frequently-used query templates can be saved for quick re-execution. Records resulting from searches and queries may be exported to a Microsoft Excel format file, printed as labels or reports, or saved in a Specify ‘Record Set’. Record Sets are logical containers which hold links to batches of specimen records for later review or action.
Field or legacy bulk data uploads are supported from Microsoft Excel files through the Specify ‘WorkBench’. The WorkBench presents a spreadsheet data entry screen which checks and validates keystroked or uploaded data against your existing database content to improve incoming data quality. Specify 6 also provides embedded georeferencing with the Tulane University’s ‘GEOLocate’ service, custom printed label and report design, and specimen data exporting.
The Specify Web Portal is a versatile module for publishing collection data to the web. Here are some nice examples of collections using the Portal at the Florida Museum of Natural History. See the Specify Add-Ons for more information about the portal.
The visual interface of Specify’s ‘Schema Mapper’ tool organizes outgoing copies of specimen records to produce data formats needed by other projects. For example, the Schema Mapper organizes specimen records as inputs to the Integrated Publishing Toolkit which in turn produces Darwin Core Archive files for publication to GBIF. To permanently identify your data records, Specify creates and maintains globally unique identifiers as UUIDs on several data types.
Specify 6 is designed to support web services links and extensions with embedded Java plug-ins. With our open-source model and management style, we invite software development collaboration ideas and proposals to add new capabilities and for stronger network integration with more inclusive computing initiatives in the earth sciences. Specify 7 was also developed in a modular, layered architecture and supports plug-ins and co-development collaboration to add new capabilities.
Make contact if you would like to evaluate Specify. Hands-on training is available, several times a year we organize Specify workshops hosted by institutions around the globe. The Specify Project can be reached by e-mail: [email protected].